Machine learning telah menjadi kekuatan yang mengubah cara kita melihat data dan pengambilan keputusan. Dalam wadah algoritma pembelajaran mesin, Support Vector Machine (SVM) merupakan salah satu metode yang paling powerful dan serbaguna. Pada artikel ini akan menjelaskan prinsip dasar SVM dan bagaimana algoritma ini digunakan dalam analisis data.
Apa itu Support Vector Machine?
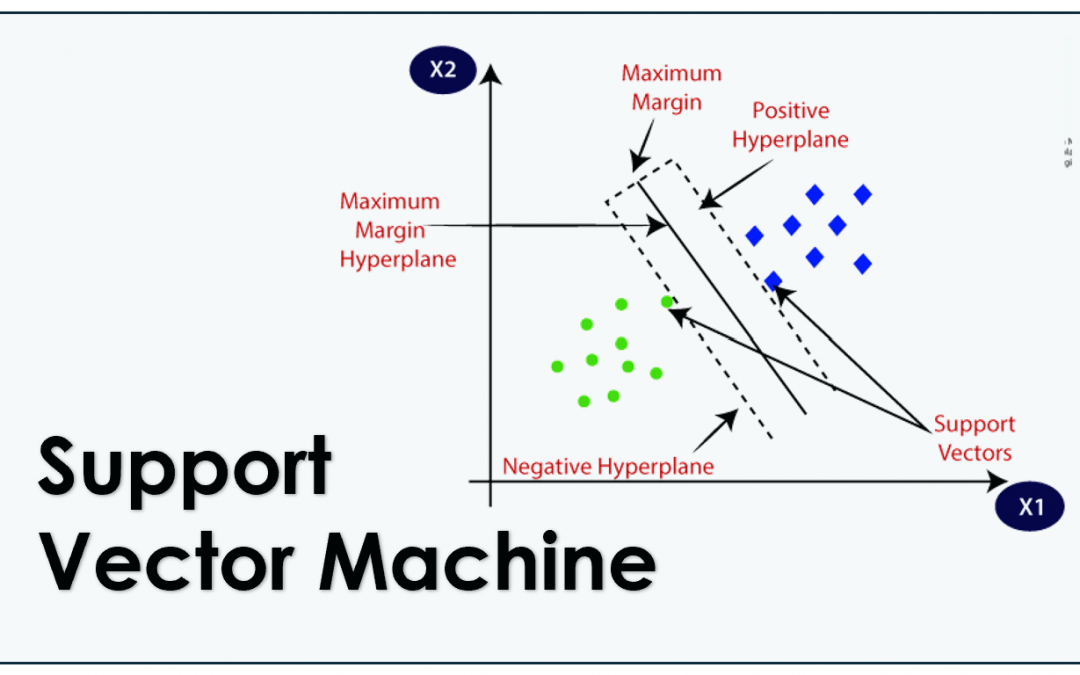
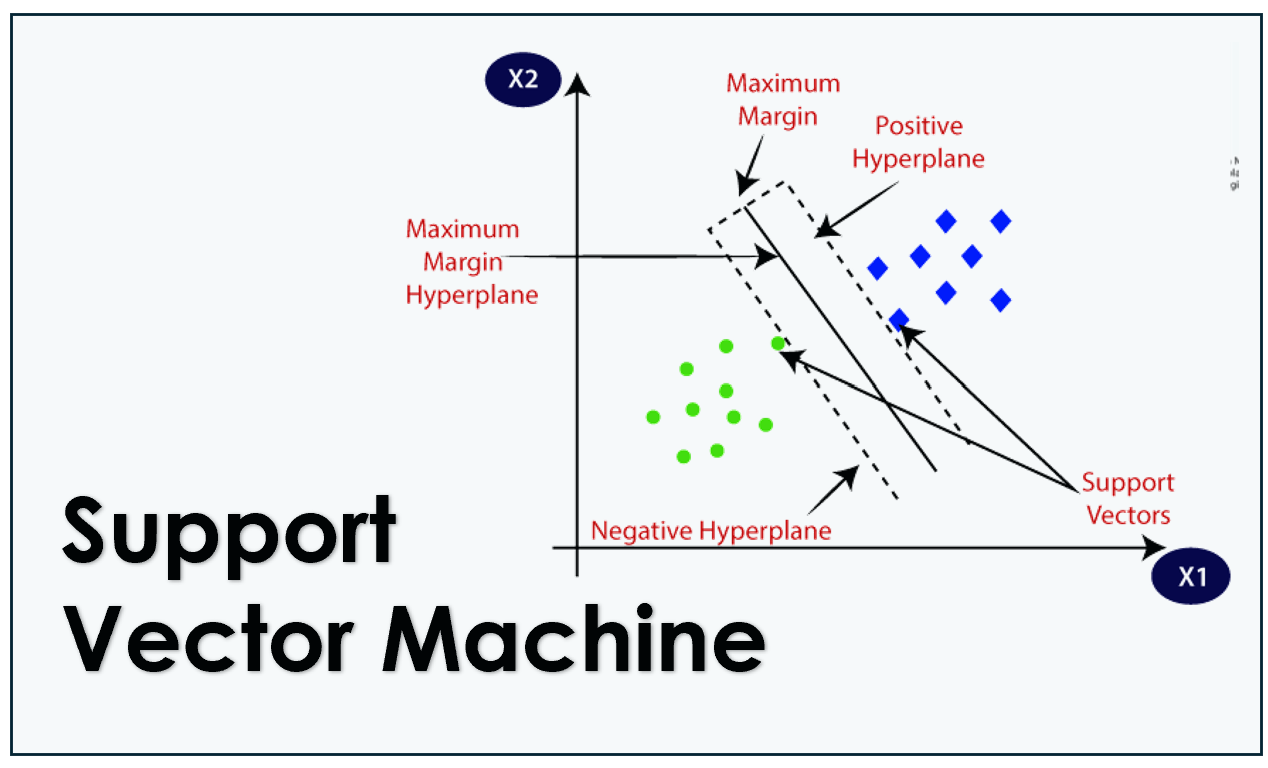
Support Vector Machine adalah algoritme pembelajaran mesin yang digunakan untuk klasifikasi dan regresi. Namun, kebanyakan dikenal karena kegunaannya dalam masalah klasifikasi. SVM bekerja dengan menemukan hyperplane atau serangkaian hyperplane dalam ruang berdimensi tinggi yang secara efektif memisahkan kelas-kelas yang berbeda dengan margin yang maksimal.
Prinsip Dasar SVM
Inti dari SVM adalah konsep margin, yaitu jarak antara hyperplane yang memisahkan data dan titik data terdekat dari kelas apa pun. Algoritma ini berusaha untuk memaksimalkan margin ini untuk meningkatkan akurasi prediksi. Ada dua komponen utama dalam SVM:
- Vektor Dukungan (Support Vectors): Titik data yang paling dekat dengan hyperplane dan menentukan posisi dan orientasi hyperplane tersebut.
- Hyperplane: Batas keputusan yang memisahkan kelas data.
Linear vs Non-linear SVM
SVM linier mencoba untuk memisahkan data menggunakan hyperplane linier. Ketika data tidak dapat dipisahkan secara linier, SVM menggunakan apa yang disebut kernel trick untuk memetakan data ke ruang berdimensi lebih tinggi di mana ia dapat dipisahkan secara linier. Kernel yang sering digunakan antara lain polinomial, radial basis function (RBF), dan sigmoid.
Penggunaan SVM dalam Analisis Data
SVM dapat digunakan dalam berbagai aplikasi, seperti:
- Pengenalan pola, seperti identifikasi sidik jari atau pengenalan wajah.
- Klasifikasi teks, seperti analisis sentimen atau kategorisasi dokumen.
- Bioinformatika, seperti klasifikasi protein atau prediksi gen.
Langkah-langkah Analisis dengan SVM
- Pemilihan Fitur: Memilih fitur yang relevan yang akan digunakan oleh model untuk klasifikasi.
- Preprocessing Data: Membersihkan data dan mengubahnya ke format yang sesuai untuk pengolahan dengan SVM.
- Pemilihan Kernel: Memilih kernel yang sesuai berdasarkan sifat data.
- Training Model: Menggunakan data pelatihan untuk melatih model SVM.
- Evaluasi Model: Menggunakan data pengujian untuk mengevaluasi efektivitas model.
- Parameter Tuning: Menyesuaikan parameter seperti C (parameter regularisasi) dan parameter kernel untuk optimasi.
Kelebihan dan Kekurangan SVM
Kelebihan:
- SVM efektif dalam ruang berdimensi tinggi dan saat ada margin yang jelas antara kelas.
- Efektivitasnya tidak menurun drastis ketika jumlah fitur melebihi jumlah sampel, menjadikannya pilihan yang baik untuk masalah dengan banyak fitur.
- Menggunakan subset dari data pelatihan dalam fungsi keputusan (vektor dukungan), membuatnya efisien secara memori.
- Versatil: berbagai fungsi kernel dapat ditentukan untuk keputusan. Kernels khusus dapat diimplementasikan untuk jenis data tertentu.
Kekurangan:
- Hasilnya tidak baik pada data yang memiliki banyak kebisingan/noise.
- SVM tidak secara langsung memberikan estimasi probabilitas seperti pada analisis regresi logistik.
- Pilihan kernel dan pengaturan parameter dapat kompleks dan memerlukan pengalaman.
Contoh Penerapan SVM
Perusahaan akan membentuk divisi baru dan berusaha mengotomatisasi proses segmentasi pelanggan, membaginya ke dalam dua segmen utama, yaitu Horeca (Hotel, Restoran & Kafe) dan Ritel (Industri Retail). Awalnya, perusahaan tidak memiliki informasi segmentasi industri pelanggan, tetapi berusaha untuk mengumpulkan data tersebut. Dengan pertumbuhan basis data pelanggan, perusahaan ingin mengembangkan model klasifikasi yang dapat secara otomatis mensegmentasikan pelanggan berdasarkan data historis pengeluaran mereka.
Masalah ini dapat diatasi dengan metode klasifikasi, seperti support vector machine. Dengan model ini, perusahaan dapat mengotomatisasi proses segmentasi pelanggan untuk mengidentifikasi apakah mereka termasuk dalam segmen Horeca atau Ritel. Hal ini membantu perusahaan dalam menghemat waktu dan biaya yang sebelumnya dikeluarkan dalam pencarian informasi secara manual.